40个数学由8支具有O4的团队组成
时间:2025-05-26 10:33 作者:bet356亚洲版本体育
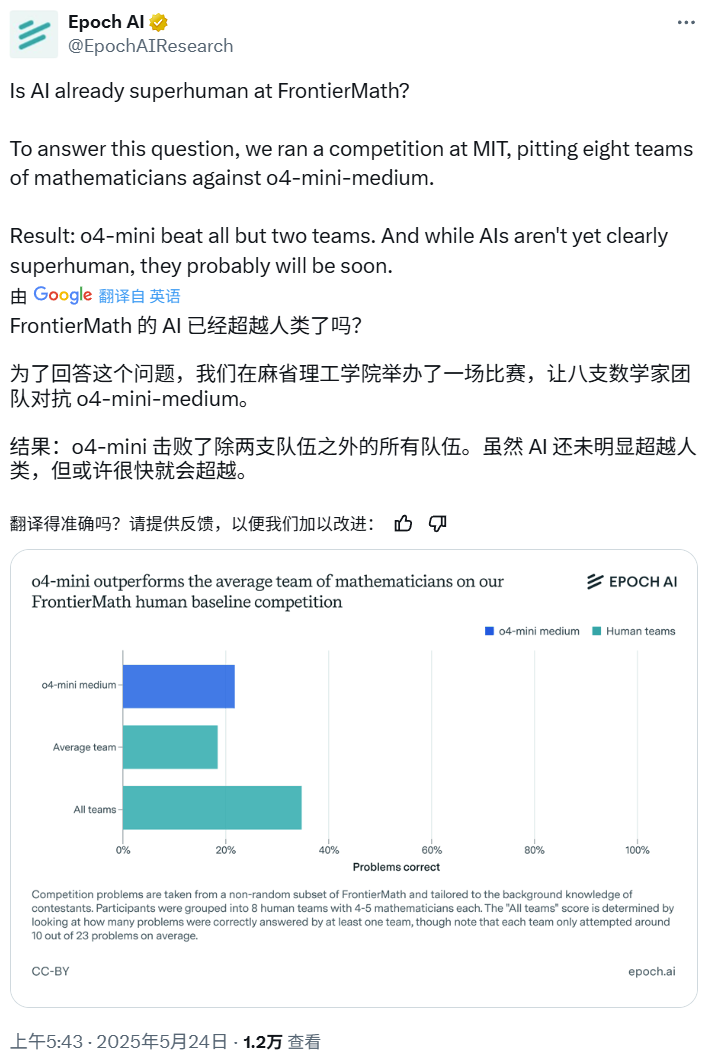
机器的心脏编辑:熊猫,最近,人工智能进入数学和编程的能力已成为很多活动,我们大多数人都悄悄地生存了下来。当它面临真正的专家时会发生什么? Epoch AI最近安排了一场艰苦的战斗:他们邀请40个数学建立了八支球队来处理OpenAi O4-Mini-Mini-Medium模型,并且测试问题来自困难的Frontiemath数据集。结果是出乎意料的:在AI中,只有8人中只有2人被击败。也就是说,O4-Mini-Medium击败了由数学专家组成的“人类团队”,得分为6:2。EpochAI毕业:“尽管AI尚未明确达到超人水平,但很快可能很快。”这个游戏吸引了很多关注。有些人认为Gemini 2.5 Pro Deep Pag认为是AI可以克服人们的AI,但是有些人支持人们,他们认为对于人类专家来说,4.5小时不足以解决困难的数学问题。你觉得abo什么ut吗?让我们详细了解“人机数学战争”。人们在Frontiermath的表现如何? Frontiermath是Epoch AI去年发布的基准测试,用于测试AI数学功能的限制。它包含300个问题,从高级本科生的水平到奖牌的获奖者都难以置信。为了确定人类的基准,Epoch AI组织了MIT竞争,邀请了近40个本科数学和具有相关领域的专家参加。参与者分为8个团队,每个团队4至5人,任务是在4.5小时时回答23个问题,并且在此过程中可以使用互联网。之后,他们在Frontiermath的基准(即O4-Mini-Medium)的基准上与表现最佳的AI系统竞争。结果是什么? O4-Mini中等大于人类团队的平均水平,但少于所有团队的总分(成功回答至少一个团队的问题的比例)。 Th因此,AI在Frontiermath中并没有取得大量超人的表现 - 但是天气认为他们很快就会前进。下图显示了人们和人工智能的总体表现。 Detailed competition results can be viewed in this spreadsheet: https://docs.google.com/spreadsheets/d/11vysj6_gv8xe9u9qb2bq9plqww0cj1hwfa7lnl-laMini-mini-mini-mini-mini-mini-mini-mini-mini-mining Edium 22%in the Human Benchmark's Benchmark竞争,超过平均水平(19%),但低于所有球队的总分(35%)。应当指出的是,至少有一个人成功地回答了O4-Mini-Medium成功回答的问题。但是,这些数据仅基于一个小的,非表达的额头子集 - 那么这对一般人类基准意味着什么? Epoch AI认为,Frontiermath中最重要的“人体基准”应在30%至50%之间,但不幸的是,这个数字只是一个估计和不清楚。下面,ePOCH AI解释了此人基准结果的四个方面,包括其来源和含义。 1。参与者并不能完全代表剪裁数学的水平。为了使高质量的研究结果毫无意义,参与者需要证明出色的数学能力。例如,满足要求的人应该具有数学医生的头衔,或者在本科级别具有过多的剩余数学奖记录。该研究将参与者分为8组,分别为4至5人,并确保每个团队在任何特定领域的学科中都有至少一名专家。这个主题的专家可能是具有毕业于该领域的学位的人,或者追求博士学位并将其列为他们的首选领域。 2。竞争的目的是测试推理的能力,而不是一般知识。竞争过程更专注于测试AI的推理能力,而不是您拥有多少知识。因此,前部银行中的问题涵盖了需要推理的数字理论和几何多样性等领域,但实际上,没有人可以同时削减所有这些学科的发展。前面的完整基准中包含的字段强调,前部优化的主要目的是AI系统是否具有数学推理能力。为了获得更多的人类基准参考,通过7个基本问题(适用于伟大的本科生)和16个高级问题(对参与专家的态度)选择了该研究,分为四个子类别:(1)拓扑,(2)代数几何,(3)组合数学数学,(4)组合数量。评分机制是正确回答高级问题的Getha 2分,正确回答关键问题只有1分。此外,在五个主要领域(基本问题类别,包括四个高级问题SubCategories),您可以在每个区域正确回答至少一个问题,从而获得额外的积分。最后,第一名获得了1,000美元,第二名获得了800美元,第三名获得了400美元。其他锦标赛将获得150美元的奖金,以鼓励他们积极参与。 3。“人类基准”的不清楚定义表明,这些团队通常解决13%至26%,平均为19%。 O4-Mini-Medium解决了大约22%的竞争问题。但是,与知识完全基于知识的完美团队相比,当前平均统计基准评分的统计数据可以在某些维度中持续估计。一种解决方案是认为,如果八个人类团队中的任何一个都得到了正确的答案,则已经正确回答了这个问题。这样做可以使人类绩效提高约35%。但是考虑到O4-Mini中的中等位置是在Pass@1设置下评估的。因此,人们可以处于这两个范围之间的范围,约20%至30%。但是,如果您想在一般基准上开发基于人的模型,则需要解决第二个问题。具体而言,分发竞争问题的困难与完整的FronerMath数据集不同,如下表所示。对于前二体竞赛和完整基准的问题的难度分布。一般的竞争问题是在1或2级的水平,而晚期问题都是3级。因此,在难度水平上研究结果并根据分布完整基准的难度来权衡总分。这将根据每个团队的平均值将基准得分提高近30%,而基于“多重试验”方法的基准得分将将基准分数提高到约52%。不幸的是,如果这种调整方法确实有效,则仍然值得怀疑,因为施加相同的重量意味着基准测试的O4-Mini-Medium标记约为37%(与19%的AI时期AI期间的完整审查)。这可能是因为竞争中1/2的问题与整个基准的平均水平的平均问题很容易相关,但是当时对于阿育斯也很难。 4。这意味着AI在前部中不会超过人,但可以轻松克服,这意味着什么?首先,我们现在知道O4-Mini-Medium标记与人类团队非常相似(至少在当前的游戏限制下),我们不知道该模型是如何做到的。 AI的答案有猜测吗?与人类相比,他们如何使用方法? Epoch说,将来将发布更多信息。其次,即使对人的相关基准实际上约为30-50%,Ai Epoch AI也认为,在今年年底之前,AI可能会显然可以生存。应当指出的是,由于游戏格式,人类的性能可以被终止。例如,如果有更多时间,人类表现可能是o显着改善。 O4-Mini-Medium大约需要5-20分钟才能完成每个问题,通常需要更长的时间。例如,参加我们赛后调查的参与者平均花了近40分钟的时间在他们喜欢的测试问题上。对机器学习活动的研究还表明,在一段时间后,人们的长期扩张行为-AI的表现将能够提高,但是人类的绩效可能会继续改善。还值得注意的是,前后问题不能直接代表实际的数学研究。但是总的来说,Epoch AI认为这是一个有用的人类基准,可以帮助评估现实世界中的前卫。参考链接https://epoch.ai/gradient-pinddates/is-i-i-i-i-laready-superhuman-on-frontiermathhtpps://x.com/epochairesearch/status/status/192603120748295794





